DevQualityEval benchmark
DevQualityEval is a standardized evaluation benchmark and framework to compare and improve LLMs for software development. The benchmark helps assess the applicability of LLMs for real-world software engineering tasks. DevQualityEval combines a range of task types to challenge LLMs in various software development use cases. The benchmark provides metrics and comparisons to grade models and compare their performance.
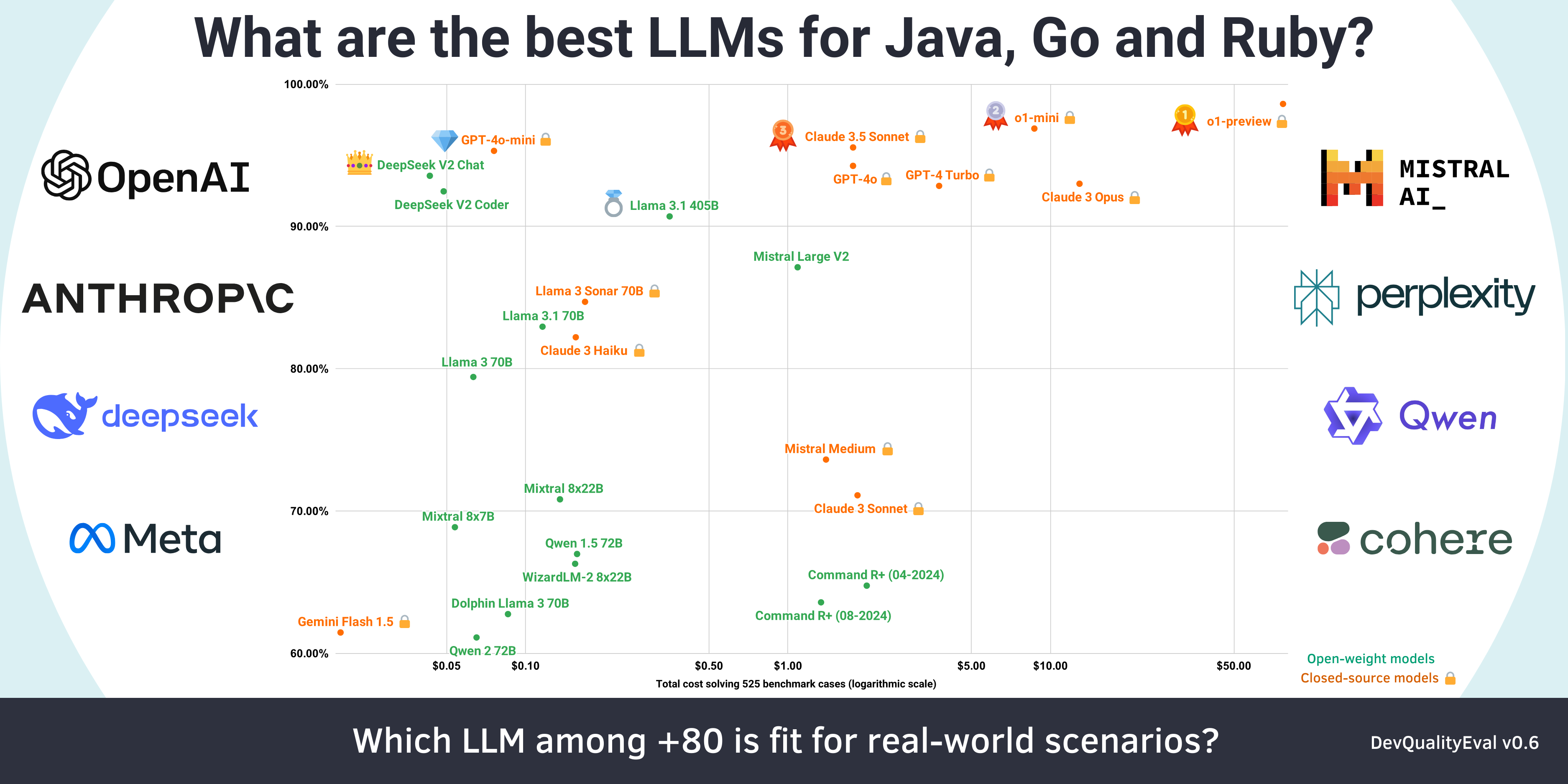
Check out the DevQualityEval leaderboard for the current list of the best-performing models, and access up-to-date, detailed results of the latest run of the DevQualityEval benchmark.
Find up-to-date details about the benchmark on the DevQualityEval GitHub page.
Deep dives into each version of DevQualityEval provide detailed insights into the results, learnings, and insights of benchmark runs:
- OpenAI's o1-preview is the king 👑 of code generation but is super slow and expensive (Deep dives from the DevQualityEval v0.6)
- DeepSeek v2 Coder and Claude 3.5 Sonnet are more cost-effective at code generation than GPT-4o! (Deep dives from the DevQualityEval v0.5.0)
- Is Llama-3 better than GPT-4 for generating tests? And other deep dives of the DevQualityEval v0.4.0
- Can LLMs test a Go function that does nothing?