DevQualityEval LLM benchmark
This page provides more information on the DevQualityEval benchmark for LLMs.
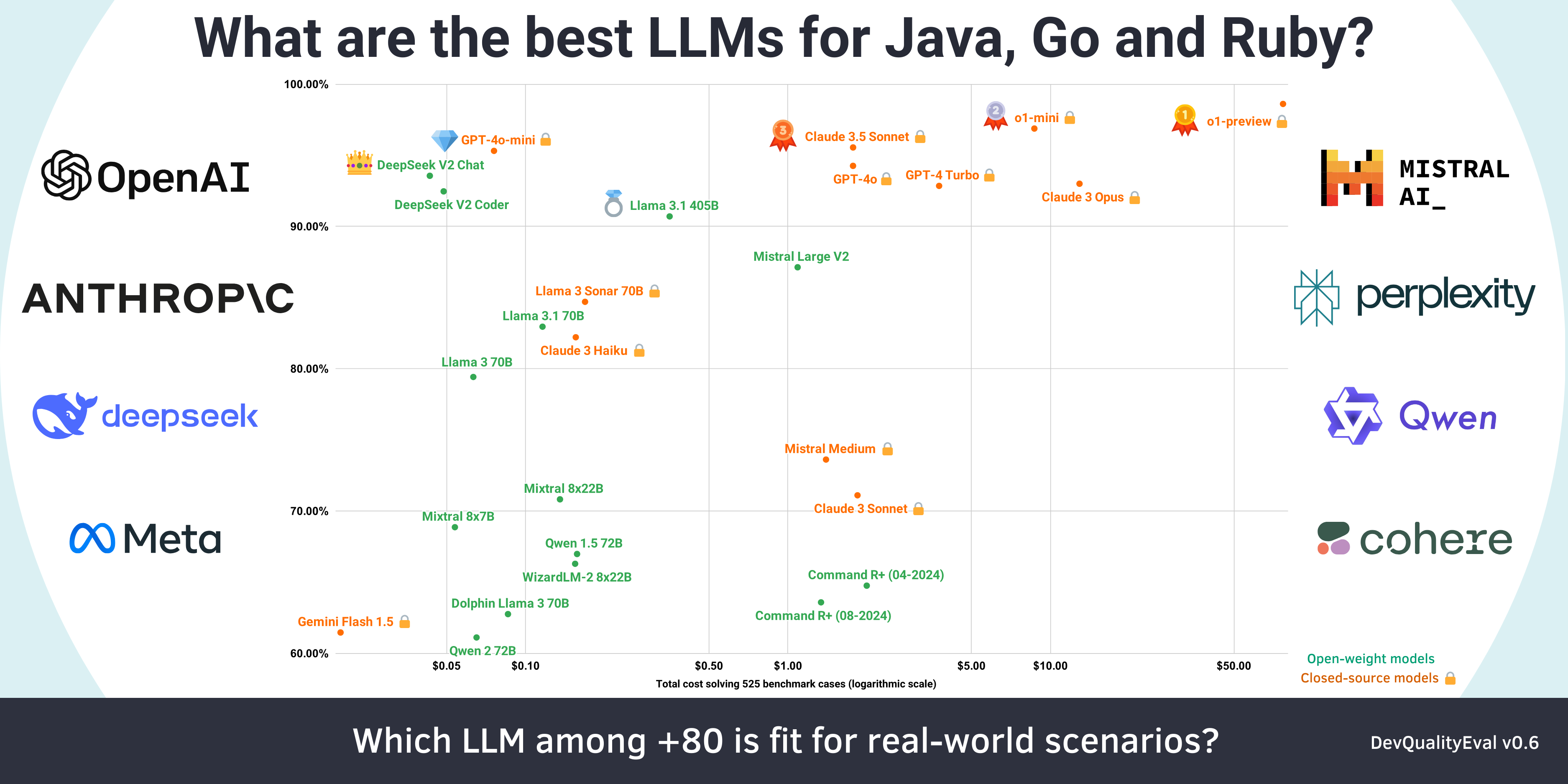
What is DevQualityEval?
DevQualityEval is a standardized evaluation benchmark and framework to compare and improve LLMs for software development. The benchmark helps assess the applicability of LLMs for real-world software engineering tasks.
DevQualityEval combines a range of task types to challenge LLMs in various software development use cases. The benchmark provides metrics and comparisons to grade models and compare their performance.
tip
For up-to-date results, check out the latest DevQualityEval deep dive. Access the DevQualityEval leaderboard for detailed results.